

Introduction: The Digital Artifact and Macro-Infrastructural Scale
The specific uniform resource locator structured as https://www.youtube.com/watch?v=0fWFetwHkVE operates not merely as a static web address, but as a dynamic, cryptographic pointer to a highly complex, multidimensional database entry residing within the world’s most expansive media distribution infrastructure. The structural composition of this locator, specifically the eleven-character alphanumeric string 0fWFetwHkVE, functions as a globally unique identifier generated through base-64 encoding mechanisms designed to ensure collision resistance across a continually expanding corpus of digital media. This atomic identifier serves as the primary relational key interlinking the raw encoded media files with vast arrays of localized metadata, subtitle tracks, dynamic engagement matrices, and heavily weighted algorithmic classification vectors.
An analysis of the architectural foundation supporting such digital artifacts reveals a staggering confluence of deep neural networks, globally distributed telecommunications hardware, and applied behavioral psychology. The digital video platform ecosystem operates on a scale unprecedented in the history of media, ingesting tens of thousands of hours of user-generated and professionally produced content every minute. This relentless influx necessitates an autonomous, continuously learning infrastructure capable of instantly processing, compressing, and categorizing media to serve a geographically dispersed user base numbering in the billions. The platform fundamentally transcends its original role as a passive video hosting service, having evolved into an active, highly deterministic curation engine that dictates the distribution of human attention, shapes global cultural narratives, and defines the contemporary digital economy.
Through the continuous tracking of user telemetry, the platform has successfully commodified visual engagement, translating the passive act of viewing into massive predictive data models. Understanding the profound societal and technical implications of such platforms requires a granular deconstruction of their internal mechanics. The architecture relies on the seamless orchestration of distinct but deeply integrated systems: the machine learning models responsible for personalized recommendation, the psychological mechanisms embedded within the user interface to maximize retention, the global server infrastructure enabling low-latency delivery, the advanced compression algorithms dictating data transmission, and the economic incentives that drive the continuous production of content. This report exhaustively analyzes these intersecting paradigms, providing a comprehensive assessment of how algorithmic video distribution fundamentally alters both the mechanics of media consumption and the structural realities of human interaction within the digital sphere.
The Evolutionary Trajectory of Recommendation Architectures
To fully grasp the current state of algorithmic determinism, it is necessary to examine the historical evolution of the platform’s recommendation logic. In the nascent stages of digital video hosting, platforms relied predominantly on chronological feeds and simplistic collaborative filtering mechanisms, such as matrix factorization, which computationally linked users and videos based on sparse matrices of explicit actions like clicks or “likes”. These early systems optimized almost exclusively for initial engagement, specifically the Click-Through Rate (CTR).
The absolute prioritization of CTR inadvertently catalyzed a platform-wide degradation of content quality. Content creators rapidly deduced that highly provocative, visually exaggerated thumbnail imagery paired with hyperbolic, misleading titles could artificially inflate click probability. This era of “clickbait” demonstrated the immediate secondary effects of algorithmic incentives on human behavior. Because the algorithm rewarded the click rather than the satisfaction derived from the subsequent media consumption, users experienced high bounce rates, leading to broad dissatisfaction and reduced overall session duration.
Consequently, platform engineers initiated a foundational paradigm shift, fundamentally rewriting the algorithmic objective function to prioritize sustained attention over initial curiosity. The metric of “watch time” became the definitive currency of the platform. By optimizing for the aggregate temporal duration a user spent engaged with a specific video—and cumulatively across a single platform session—the algorithm began to organically surface content that delivered genuine narrative or intellectual value relative to its initial promise. This architectural shift effectively forced the global creator ecosystem to adapt, systematically punishing deceptive packaging and rewarding long-form storytelling, rigorous pacing, and sophisticated retention mechanisms. However, as the user base expanded into the billions and the content corpus scaled exponentially, traditional collaborative filtering systems encountered severe computational bottlenecks, necessitating the transition to modern Deep Neural Network (DNN) architectures.
The Dual-Layer Deep Learning Architecture
The foundational challenge of modern algorithmic video recommendation is rooted in the mathematics of extreme scale. Traditional algorithms become computationally intractable when forced to process billions of active client nodes against a continuously expanding corpus of billions of video assets in real-time. To resolve this severe latency bottleneck, the recommendation architecture is structurally bifurcated into two specialized deep neural networks operating sequentially: the candidate generation network and the ranking network.
Candidate Generation Networks and Latent Space Projections
The candidate generation model functions as a highly efficient, coarse-grained filtering funnel. Its primary objective is to evaluate the entirety of the platform’s media corpus and rapidly isolate a manageable subset—typically numbering in the hundreds—of highly relevant video candidates for a specific user at a specific millisecond in time. This network treats the recommendation process as an extreme multi-class classification problem. By synthesizing the user’s historical telemetry, including granular data such as cumulative watch time, sequential search query strings, localized demographic indicators, and real-time device states, the network projects the user’s current behavioral state into a dense, high-dimensional latent space.
The mathematical formulation utilized by the candidate generation model to predict the likelihood of a user watching a specific video within a given contextual state
is classically modeled using a specialized softmax classifier:
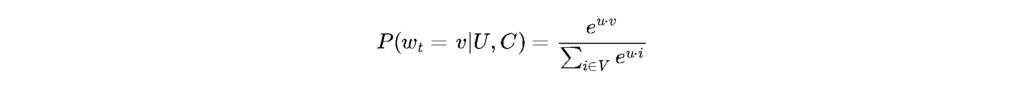
Within this equation, the variable represents the high-dimensional vector embedding of the user’s contextual and historical profile, while
represents the corresponding vector embedding of the candidate video. Because the denominator requires computing the sum over the entire video corpus
, exact mathematical calculation during real-time serving is computationally impossible within the required single-digit millisecond latency threshold. Therefore, the infrastructure relies extensively on Approximate Nearest Neighbor (ANN) search algorithms, utilizing specialized hashing techniques and hierarchical probabilistic trees to drastically reduce lookup times.
The success of this layer depends entirely on the spatial orientation of the embeddings within the latent space. Videos that are frequently co-watched by highly correlated user cohorts are positioned in extremely close topological proximity, creating clusters of localized semantic and behavioral meaning. Consequently, when a user accesses the initial URL 0fWFetwHkVE, their historical user vector interacts dynamically with the vector representation of that specific video, instantaneously shifting their trajectory within the multidimensional space and subsequently altering the composition of their future candidate generation outputs.
| System Layer | Primary Algorithmic Objective | Input Feature Dimensionality | Output Scope | Maximum Allowable Computational Latency |
| Candidate Generation | High recall, extreme filtering | Coarse user history, broad embeddings | ~500 highly relevant candidates | < 10 milliseconds |
| Ranking Mechanism | High precision, engagement optimization | Granular historical data, context features | Ordered list of ~50 videos | < 50 milliseconds |
| Secondary Re-Ranking | Diversity, policy enforcement, novelty | Policy tags, historical exposure | Final user-facing interface layout | < 10 milliseconds |
The Ranking Mechanism and Multi-Objective Optimization
Following the rapid isolation of a candidate pool, the secondary ranking network applies a fine-grained, highly parameterized analysis to assign an exact probability score to each potential video, ultimately determining the absolute vertical order in which content is presented on the client application. The ranking architecture evaluates thousands of disparate features, encompassing both continuous and categorical variables. Continuous features typically include the exact temporal duration since the user last consumed media within a similar semantic cluster, the historical click-through rate of the specific video across the broader population, and the variance in the user’s sequential engagement patterns. Categorical features incorporate variables such as the user’s preferred application language, the localized geographic constraints of their current IP address, and the specific hardware decoding capabilities of the user’s device.
While the expected watch time remains a foundational metric, modern ranking systems have evolved beyond simple linear regression models to employ Multi-gate Mixture-of-Experts (MMoE) architectures designed to perform sophisticated multi-objective optimization. The platform cannot solely optimize for duration; it must simultaneously optimize for user satisfaction (explicitly measured through likes, shares, and survey responses) while aggressively penalizing negative user signals (such as swift abandonment or explicit “do not recommend” actions).
The expected aggregate utility optimization can be conceptualized through a parameterized objective function that weights multiple predicted outcomes:
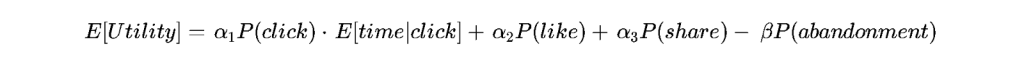
In this formulation, the network computes the probability of an initial click and multiplies it by the predicted duration of engagement conditional upon that click occurring
. The parameters
represent continuously tuned weights assigned to positive engagement vectors, while
represents a severe mathematical penalty applied to behaviors indicative of clickbait or user frustration. This complex interplay ensures that the resulting chronological feed presented to the user represents the absolute global optimum of predicted behavioral retention for that specific millisecond.
Telemetry, Matrix Factorization, and Behavioral Surveillance
The overarching effectiveness of both the candidate generation and ranking architectures is entirely contingent upon the relentless, high-velocity extraction of highly granular user telemetry. The platform operates fundamentally as a ubiquitous, planetary-scale data surveillance apparatus. While users consciously understand that explicit actions—such as clicking a video or leaving a localized comment—are permanently recorded, the invisible data extraction pipeline is infinitely more comprehensive and invasive.
The client application, whether deployed on a mobile operating system or a desktop browser, silently records vast arrays of micro-interactions. These include the exact cursor hover durations over specific thumbnail images, the precise millisecond a user initiates a scrolling action, localized volume adjustments made during specific narrative beats, the rate of playback speed alteration, and the detailed gyroscope data generated by mobile hardware. Through the application of complex matrix factorization techniques and deep learning embeddings, this massive, unstructured data lake is continuously distilled into highly predictive behavioral profiles.
A standard foundational approach utilized to decode hidden latent features within this massive telemetry data is modeled through regularized matrix factorization:
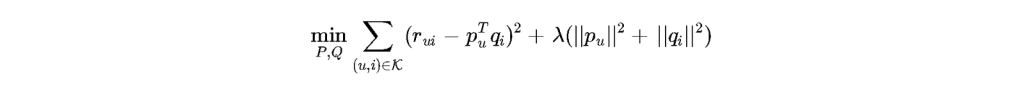
In this equation, the system continuously minimizes the error between the observed user engagement and the predicted engagement derived from the dot product of the user matrix
and the item matrix
. The regularization parameter
serves a critical function: it prevents the deep learning model from perfectly memorizing historical statistical noise (overfitting), forcing the architecture to isolate the true underlying psychological preferences and predictable behavioral archetypes of the user base. This architectural capacity to predict human behavior with staggering mathematical accuracy grants the platform immense, largely unregulated power to subtly modify consumer preferences and accurately forecast aggregate cultural trends.
Physical Infrastructure: Global Content Delivery Networks
The theoretical and mathematical sophistication of the recommendation algorithm is entirely dependent upon the physical reality of the global network infrastructure required to execute media delivery without prohibitive latency. When a client application initiates a request for a specific resource, such as the media tied to the identifier 0fWFetwHkVE, the sheer volume of data prevents the request from being routed to a singular, centralized datacenter. Instead, the platform relies on one of the most expansive and sophisticated Content Delivery Networks (CDNs) in human history.
Anycast Routing and Edge Computing Topologies
The foundational principle of the CDN architecture is the geographic decentralization of data caching through massively distributed Points of Presence (PoPs). Through the use of Border Gateway Protocol (BGP) routing and Anycast DNS protocols, a user’s initial video request is instantaneously directed to the physical edge server located geographically and topologically closest to the user’s localized Internet Service Provider (ISP). If the requested video possesses a high degree of contemporary popularity within that specific regional cluster, it will likely reside within the high-speed solid-state cache of this edge node, allowing for instantaneous, high-bandwidth data delivery.
However, if the requested artifact belongs to the massive “long tail” of niche, obscure, or historically older media, a cache miss occurs at the edge tier. The edge server must subsequently query intermediate mid-tier caches or, ultimately, the deep storage origin clusters to retrieve the necessary encoded data chunks. To manage limited cache space optimally, edge servers employ sophisticated eviction algorithms, frequently moving beyond standard Least Recently Used (LRU) models to implement machine-learning-driven predictive caching, which anticipates regional viral spikes before they fully materialize.
This physical infrastructure organically acts as a silent, secondary curation mechanism. Because highly viral content is globally cached at the outermost edge nodes, it plays with near-zero buffering and maximal visual fidelity, subtly reinforcing positive physiological user experiences. Conversely, hyper-niche content natively suffers from marginal increases in latency and buffering probabilities due to the necessity of deeper database retrieval across transnational fiber-optic networks. This latency slightly degrades the user experience, subtly contributing to lower overall expected watch time metrics and thereby reinforcing the algorithmic dominance of mainstream media.
Adaptive Bitrate Streaming and Compression Algorithms
To successfully manage the chaotic, asymmetrical, and highly fluctuating nature of global internet bandwidth, the platform relies strictly on Adaptive Bitrate Streaming (ABR) architectures. During the initial upload phase, the continuous source video file is rigorously processed and fragmented into discrete temporal segments, typically ranging from two to ten seconds in absolute duration. Each individual segment is simultaneously transcoded into a massive matrix of variable resolutions and compression bitrates utilizing advanced video coding standards.
The client application operates as a highly autonomous agent, continuously monitoring its own internal buffer capacity and the real-time throughput of the user’s localized network connection. The ABR client utilizes highly complex mathematical utility functions to dynamically select the optimal bitrate for the next temporal segment, balancing the necessity for high visual quality against the absolute prohibition of catastrophic buffer depletion (rebuffering).
A standard mathematical representation of the ABR client utility function is modeled as follows:
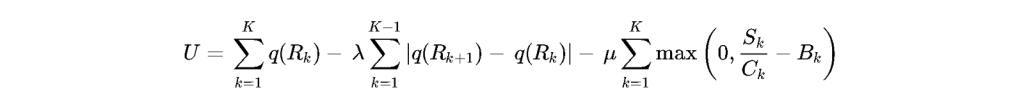
In this utility maximization equation, the variable models the perceived visual quality of chunk
encoded at a specific bitrate
. The secondary term, parameterized by
, severely penalizes rapid fluctuations in visual quality between sequential chunks, ensuring a consistent visual experience. The final term, parameterized by
, represents the absolute penalty applied to rebuffering events, calculated continuously utilizing the individual segment size
, the instantaneous channel bandwidth capacity
, and the current client buffer fill level
.
| Video Coding Standard | Compression Efficiency Benchmark | Decoding Computational Complexity | Primary Architectural Use Case |
| H.264 / AVC | Baseline Standard (1.0x) | Extremely Low (Universal Hardware) | Legacy devices, low-power mobile, ubiquitous fallback |
| HEVC / H.265 | High (~1.5x better than AVC) | High (Requires specialized silicon) | High Dynamic Range (HDR) content, 4K premium delivery |
| VP9 | High (~1.5x better than AVC) | Moderate to High | Default standard for high-definition web streaming |
| AV1 | Ultra-High (~1.3x better than VP9) | Extremely High (Emerging hardware) | Next-generation bandwidth reduction, 8K streaming |
To execute this massive transcoding operation economically, platforms have increasingly abandoned general-purpose central processing units (CPUs) in favor of proprietary, application-specific integrated circuits (ASICs). Hardware accelerators, such as specialized Video Coding Units (VCUs), allow the infrastructure to ingest and compress exabytes of video data exponentially faster and with significantly lower thermal and energetic profiles than traditional computational hardware.
The Creator Economy and Algorithmic Labor
The intersection of platform architecture and human labor has birthed an entirely new macroeconomic paradigm globally recognized as the creator economy. Independent producers who consistently upload media are not merely participating in social expression; they are functioning as hyper-agile digital enterprises dynamically responding to shifting algorithmic incentives. The platform facilitates this immense production volume through programmatic revenue-sharing mechanisms, primarily distributing a calculated percentage of advertisement revenue directly to the channels that successfully generate high aggregate user watch times.
Monetization Paradigms and the Sunk-Cost Fallacy
The architecture of monetization forces creators into a relentless, cyclical production cycle. Because the deep neural network heavily privileges recent uploads and consistent publishing schedules to maintain absolute user engagement baselines, creators who deviate from rigid upload cadences experience immediate, often severe mathematical reductions in algorithmic impression distribution. This dynamic instills a profound psychological sunk-cost fallacy within the global creator cohort. Having invested significant temporal, creative, and financial capital into building a specific audience vector within the platform’s latent space, creators become psychologically bound to continuous production out of a highly rational fear that their algorithmic relevance will aggressively decay.
Furthermore, the inherent volatility of programmatic advertisement rates—which fluctuate wildly based on macroeconomic trends, seasonal advertising budgets, and corporate brand-safety concerns—forces professional creators to heavily diversify their commercial architectures. To stabilize income, creators seamlessly integrate direct brand sponsorships, sophisticated affiliate marketing structures, and direct-to-consumer merchandise sales into their video narratives, structurally transforming the underlying media artifact into a multi-layered commercial vehicle.
| Revenue Paradigm | Economic Mechanism | Algorithmic Dependency | Predictability and Variance Profile |
| Programmatic AdSense | Pre-roll and mid-roll automated ad insertion | Extremely High (Requires massive scale) | Highly volatile, dependent on macro advertising seasons |
| Direct Sponsorship | Host-read embedded advertisement | Moderate (Requires established niche authority) | Stable per contract, highly insulated from platform demonetization |
| Channel Memberships | Monthly recurring micro-transactions | Low (Relies heavily on core community retention) | Highly predictable, insulated from broad traffic drop-offs |
| Affiliate Marketing | Commission earned on generated outbound sales | Moderate | Variable, highly dependent on underlying product conversion rates |
Audience Capture and Parasocial Architecture
The relentless pursuit of algorithmic favor significantly impacts the fundamental psychological relationship between the creator and the consumer. To maximize the expected watch time metric, creators engineer deep parasocial dynamics—asymmetrical relationships wherein the viewer feels a profound sense of intimacy, trust, and friendship with the digital persona. This is structurally achieved through highly deliberate cinematographic techniques: direct-to-camera eye contact, the simulated exhibition of unscripted vulnerability, spatial proximity to the lens, and continuous self-referential callbacks to deeply entrenched community inside jokes.
However, this parasocial architecture leads directly to the restrictive phenomenon of “audience capture”. As the deep learning recommendation system groups the creator’s audience into a highly specific, statistically rigid behavioral cluster, the algorithm begins exclusively rewarding the creator for producing content that perfectly aligns with the prior expectations of that exact demographic. If a creator attempts to shift their intellectual focus, alter their aesthetic, or introduce contradictory viewpoints, the immediate reduction in initial click-through rates and average view duration signals to the ranking layer that the content is mathematically failing. The algorithm subsequently halts distribution, organically punishing artistic evolution and locking the creator into a static, repetitive intellectual loop strictly demanded by the localized preferences of their hyper-optimized audience.
Psychological Engineering: Operant Conditioning and Frictionless Design
The algorithmic environment of the platform functions as an applied system of behavioral economics that actively and deliberately shapes human cognition. When a user interfaces with a digital artifact, they are immediately submerged within a carefully orchestrated digital architecture explicitly designed to minimize navigational friction and maximize sustained physiological attention. This architectural philosophy relies heavily on established principles of operant conditioning, specifically the deployment of variable ratio schedules of reinforcement originally mapped in mid-twentieth-century behavioral psychology.
Because the user cannot perfectly predict which recommended video will deliver the highest degree of psychological satisfaction, intellectual stimulation, or comedic relief, the act of scrolling and selecting becomes a highly probabilistic endeavor. This unpredictability triggers dopaminergic reward loops identical to those observed in classical gambling environments. The platform further reduces human agency through the implementation of automated continuity features, most notably the frictionless autoplay mechanism. By automatically initiating the sequential playback of the next algorithmically ranked video the instant the current video concludes, the interface shifts the cognitive burden of action from the active decision to “continue watching” to the active decision to “cease watching”.
This subtle manipulation of default behavioral inertia significantly increases aggregate session times, thereby maximizing the total volume of inventory available for programmatic advertisement insertion. The platform does not ultimately view the video file as the primary commercial product; rather, the deeply analyzed, highly predictable behavioral attention of the user cohort constitutes the true asset traded within the platform’s real-time advertising bidding exchanges. The content itself serves merely as the necessary sensory substrate required to harvest, refine, and package human attention for corporate consumption.
Algorithmic Moderation, Content Governance, and Legal Frameworks
To mitigate the rapid global proliferation of policy-violating material, ranging from extreme graphic violence to coordinated geopolitical misinformation, the platform is forced to deploy massive, completely automated moderation pipelines. The sheer volume of uploaded media—frequently exceeding hundreds of hours per minute—renders human-in-the-loop moderation mathematically impossible at the initial ingestion phase. Consequently, the infrastructure relies heavily on complex machine learning classifiers, sophisticated visual perceptual hashing networks, and advanced Natural Language Processing (NLP) models operating on automatically transcribed audio tracks.
The automated moderation architecture is permanently trapped within a statistical precision-recall tradeoff, a fundamental mathematical dilemma that dictates platform safety.
| Moderation Threshold State | Precision Implication | Recall Implication | Secondary Societal and Economic Effect |
| High Confidence Required (Strict) | High Precision (Extremely few false positives) | Low Recall (Misses substantial volumes of harmful content) | Proliferation of borderline policy violations, extremist media, and platform-wide toxicity |
| Low Confidence Required (Loose) | Low Precision (Massive volume of false positives) | High Recall (Catches almost all explicitly harmful content) | Widespread collateral damage, aggressive censorship of legitimate journalism, and devastating demonetization of compliant creators |
If platform engineers configure the machine learning classifiers to demand extreme statistical confidence before executing an automated punitive takedown or demonetization event, the precision of the system is high, meaning very few innocent videos are erroneously removed. However, the recall metric drops significantly, allowing heavily obfuscated hate speech, nuanced algorithmic misinformation, and graphically violent media to easily bypass the digital filters and achieve rapid viral distribution. Conversely, if the system lowers the confidence threshold to aggressively cleanse the platform, the resulting tidal wave of false positives devastates the creator economy, inadvertently censoring legitimate geopolitical reporting, crucial educational material, and highly contextualized satirical expression.
This moderation complexity is further compounded by localized legal frameworks. In jurisdictions governed by protections such as Section 230 of the Communications Decency Act in the United States, the platform enjoys broad immunity from liability for the content generated by its users, allowing the algorithm to operate with significant latitude. However, emerging global legislation, such as the European Union’s Digital Markets Act (DMA) and Digital Services Act (DSA), threatens to impose severe regulatory oversight on the foundational algorithmic ranking structures, potentially forcing platforms to completely re-architect their recommendation objective functions to comply with regional transparency mandates. To navigate this, platforms frequently employ “shadowbanning” or algorithmic demotion—whereby content is not explicitly deleted but its latent space vector is severely penalized, mathematically ensuring it is never surfaced in candidate generation pipelines, thus technically maintaining hosting compliance while virtually eliminating distribution.
Epistemological Shifts and the Fragmentation of Consensus
The aggregation of billions of personalized, heavily insulated recommendation loops creates profound macroscopic shifts within global society. The fundamental architecture of collaborative filtering operates by predicting future behavior almost entirely based on historical preference, inherently creating closed-loop information topologies. The societal implications of this mathematical reality extend far beyond entertainment, fundamentally disrupting modern epistemological consensus and the baseline realities required for democratic discourse.
Because the primary objective function strictly optimizes for maximized aggregate viewing duration, the algorithm systematically surfaces media that perfectly aligns with the user’s pre-existing cognitive biases and ideological predispositions. Content that challenges a user’s worldview frequently induces intense cognitive dissonance, predictably resulting in rapid session abandonment and mathematically poor expected watch time metrics. Consequently, the deep learning network rapidly learns to insulate the user from contradictory perspectives, building an impenetrable algorithmic echo chamber or “filter bubble”.
The massive second-order effect of this systemic bias confirmation is the absolute fragmentation of shared societal reality. As geographically adjacent individuals are computationally sorted into increasingly disparate informational silos by hyper-efficient algorithms, the baseline epistemic foundations required for coherent societal debate evaporate. Furthermore, the algorithm organically discovers—without any explicit programming—that highly emotive, polarizing, and outrage-inducing content generates significantly higher sustained physiological engagement rates than nuanced, highly contextualized, or academic analysis. This architectural reality inadvertently transforms the recommendation engine into an automated radicalization funnel, slowly migrating targeted users from mainstream digital artifacts toward increasingly extreme, fringe content clusters purely in the mathematically blind pursuit of marginal increases in session duration.
Short-Form Disruption: The Transition to High-Velocity Micro-Stimuli
The macro-architectural stability of traditional long-form video consumption has recently experienced massive, systemic disruption due to the aggressive global rise of the short-form, continuously scrolling video format. In direct response to competing global platform ecosystems monopolizing younger demographic attention spans, the foundational recommendation architecture was heavily modified to support vertical, hyper-condensed media consumption loops.
The socio-technical implications of short-form video represent a distinct, radical divergence from the expected watch time optimization models utilized for long-form content. Within the short-form interface, absolute session duration per video is no longer a viable or informative metric, as the media artifacts frequently resolve completely within fifteen to sixty seconds. Consequently, the ranking neural network shifted its primary optimization parameters aggressively toward absolute completion rate percentage, repeat loop counts, and rapid binary feedback indicators.
This specific architectural shift severely intensifies the dopaminergic feedback loops embedded within the behavioral economy. The physical and cognitive friction involved in transitioning between discrete media artifacts is entirely eradicated by the vertical swipe interface, massively accelerating the speed at which users are bombarded with novel visual stimuli. As the recommendation model is fed massive volumes of binary feedback data at a drastically accelerated rate, the deep learning clusters achieve an unparalleled degree of granular personalization in a fraction of the historical time. However, this relentless algorithmic optimization for immediate, micro-attentional capture fundamentally erodes the baseline human capacity for sustained, deep cognitive engagement. It further fragments complex digital narratives into chaotic, disconnected bursts of highly arousing but intellectually shallow visual data, dramatically accelerating the cultural half-life of global trends.
The Generative AI Paradigm: Synthetic Media and Future Topologies
The immediate and long-term horizon of digital video platforms is entirely defined by the deep integration of vast Large Language Models (LLMs) and highly advanced generative artificial intelligence frameworks directly into the platform substrate. The platform architecture is rapidly transitioning from a passive system that merely hosts and curates deterministically produced human media to an active, sovereign system capable of dynamically generating, altering, hallucinating, and translating media in real-time.
The deployment of sophisticated neural dubbing architectures immediately disrupts the traditional geographic and linguistic limitations of digital media. Utilizing complex voice-cloning techniques and localized lip-sync interpolation networks, a video file originated by a creator in English can be instantaneously, synthetically translated into dozens of global dialects. Crucially, this synthetic translation perfectly preserves the unique tonal inflections, pacing, and physiological cadences of the original creator. This breakthrough artificially shatters localized content silos, forcing domestic creators to instantaneously compete within a hyper-saturated, violently unified global attention market, fundamentally altering the economics of regional media production.
Furthermore, the introduction of completely synthetic, text-to-video generative AI tools profoundly alters the fundamental economic barrier to entry for content creation. As the computational cost and technical friction required to generate hyper-realistic, narratively complex digital media trends rapidly toward zero, the platform architecture will face an unprecedented, exponential explosion in total inventory volume. The candidate generation and ranking networks will subsequently be forced to completely re-evaluate their mathematical parameters. When visual fidelity and high-production value become ubiquitous and essentially free commodities, the algorithm will likely be forced to pivot, prioritizing the cryptographic authenticity, established parasocial trust, and absolute mathematical provenance of the media artifact over mere sensory stimulation. This shift signals the next evolutionary epoch of the platform, where verifying reality becomes more computationally expensive than generating it.
Conclusion
The global digital video platform, encapsulated by a seemingly simple URL mechanism, represents one of the most overwhelmingly complex socio-technical architectures ever constructed by human engineering. An exhaustive analysis of its intersecting constituent mechanisms reveals a hyper-optimized ecosystem wherein transnational telecommunications infrastructure seamlessly intertwines with the advanced mathematical manipulation of human behavioral psychology. The historical transition from simplistic collaborative filtering models to vast, dual-layered deep neural networks explicitly optimizing for massive aggregate expected watch times has fundamentally and permanently altered the trajectory of digital culture. The mathematically rigid parameters of candidate generation and deep ranking networks strictly dictate the economic viability of millions of independent content creators, actively enforcing strict behavioral norms and standardizing narrative structures across the globe.
Simultaneously, the physical realities of edge caching topologies, BGP routing, and adaptive bitrate streaming silently dictate the immediate flow of digital media, structurally privileging viral continuity over niche or academic distribution. While this immense technical architecture has radically democratized content creation and enabled unprecedented global connectivity, the second and third-order epistemological consequences are extraordinarily severe. The continuous, algorithmically blind optimization for prolonged session engagement inherently silos human populations into distinct, highly polarized ideological clusters, systemically eroding the foundational shared reality required for democratic societal cohesion.
Furthermore, the relentless extraction of deep behavioral telemetry grants the underlying algorithmic infrastructure massive, opaque, and highly unregulated influence over macro-level human behavior. As the underlying deep learning networks rapidly integrate with real-time generative artificial intelligence frameworks, the fundamental boundaries delineating authentic human expression, mathematical algorithmic determinism, and synthetic digital reality will only continue to dissolve. The platform has evolved far beyond a repository for digital artifacts; it has become a deterministic, mathematically governed sovereign entity that holds unprecedented sway over the psychological and cultural direction of modern human civilization.






